View project details
To view details for an individual job cluster optimization project:
- Select the Project Name for a project from the Projects table.
The main section of the Project details page displays summary metrics, the current optimization phase and status, a Cost utilization chart, and a Runtime chart for the selected project.
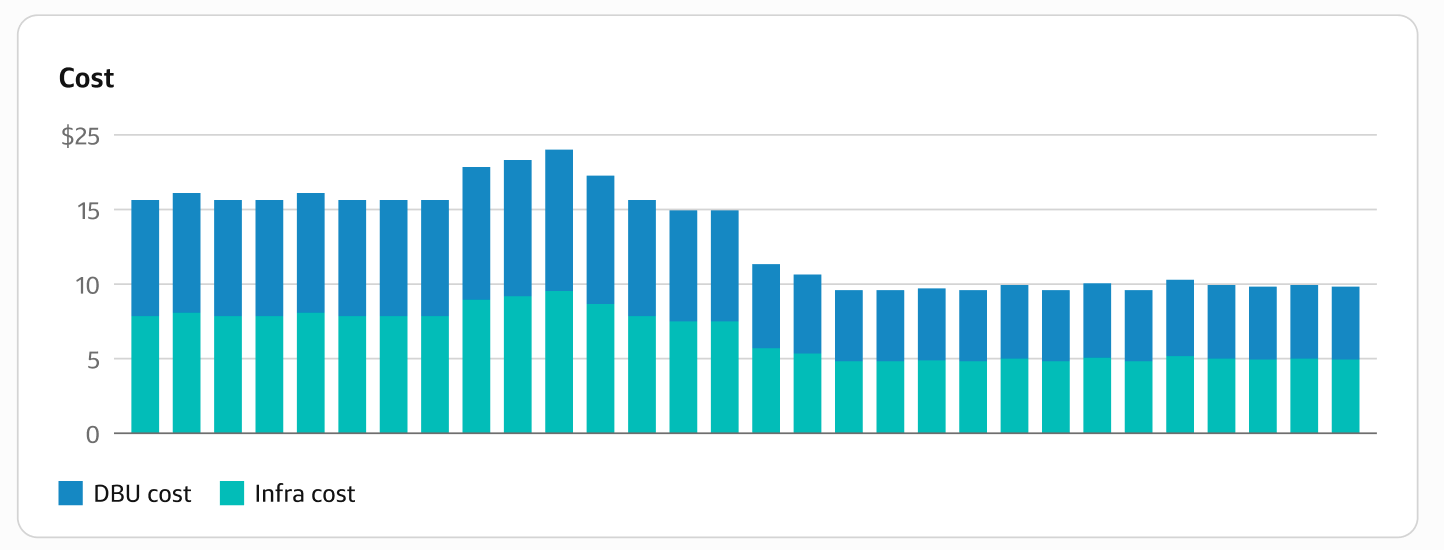
Job cluster optimization costs are calculated differently from other costs shown in Slingshot.
- For DBU costs, job cluster optimization calculates costs based on job cluster size and runtime, whereas the rest of Slingshot uses system tables from Databricks.
- For infrastructure (cloud provider) costs, job cluster optimization calculates costs based on cloud provider list prices and cluster monitoring (e.g. AWS Eventbridge, Azure Eventgrid) / timeline (e.g. when a node joined / left the cluster), whereas the rest of Slingshot uses cloud provider APIs (e.g. AWS Cost Explorer API), which accounts for customer discounts.
- Additionally, job cluster optimization only shows costs for job clusters onboarded to job cluster optimization and the rest of Slingshot shows costs for all jobs in onboarded metastores.
Summary metrics for the selected project include:
- Savings to date: The total amount of savings on this project since optimization started.
- Projected annual savings: The total amount of savings expected for your project for the next 12 months, based on activity up to today.
- Engineering hr savings: The time saved on manually tuning job clusters, as a result of enabling job cluster optimization.
- Total cost: The total cost of running this project since optimization started.
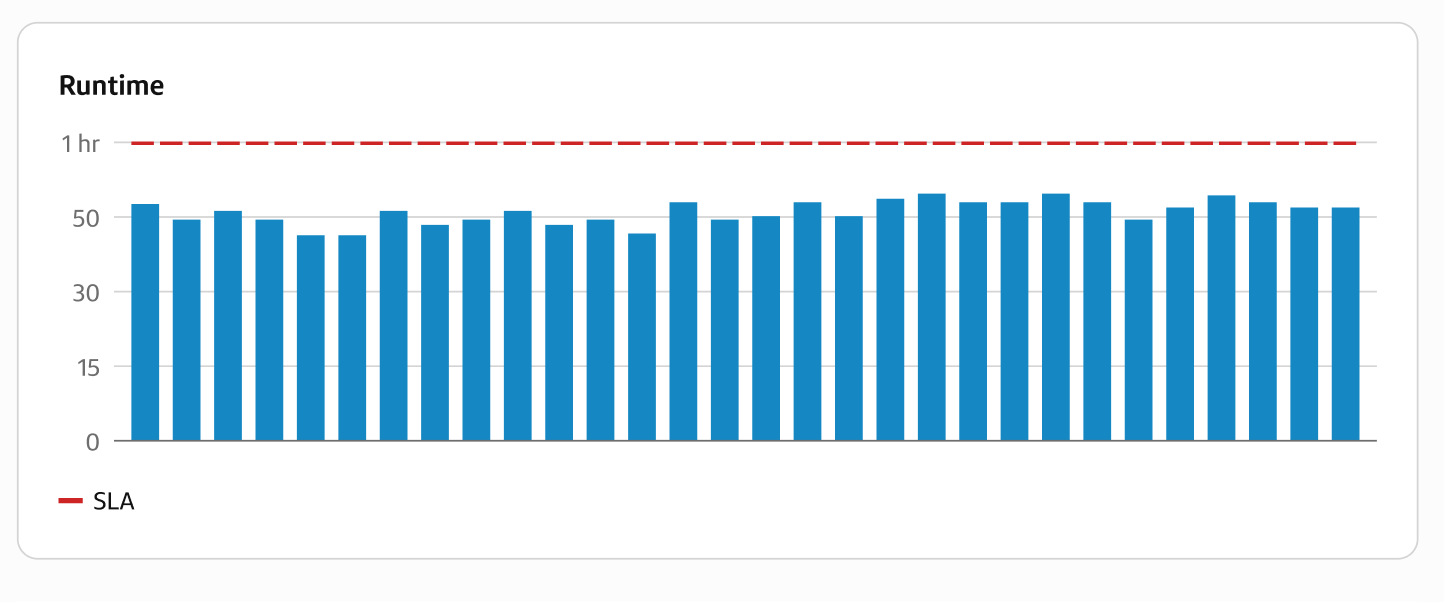
- SLAs met: The percentage of successful runs that completed within the Service Level Agreement (SLA) requirements. Calculated as a ratio of all runs for this project.
The Optimization phase displays in the top right. These phases include:
- Learning: Slingshot is trying to understand how changes to your cluster affect your cost and run-time.
- Optimizing: Slingshot begins to adjust your cluster configuration to reduce cost while meeting your SLAs (if any).
- Pending setup: Slingshot is in process of collecting the first set of data on your cluster.
- Rebasing: Slingshot is updating the hardware basis used to calculate the optimization recommendation.
The right sidebar of the Project details page provides additional information, including:
- Details: The optimization Phase, project Type, Project ID, and Databricks job ID for the project.
- Optimization settings: The recommended Service level agreement time and settings for Auto-apply recs, Maintain scaling type, and Worker instance recs.
- Insights: Displays additional best-practice insights for your project.
You can customize the data in both the Cost cost and Runtime table by:
- Number of job runs shown: Select the number of job runs you want to show from the dropdown.
Project cost details
The Cost chart on the Project details page breaks down the total project cost by DBU cost and Infra cost for each job run.
Project runtime details
The table on the Projects page lists all your job cluster optimization projects by Project Name, App ID, Insights, Last monitored, Last run spark cost, Optimization phase, and Last run status.
- Select a column heading to sort the table by that field.
- Select Filters or use the Search bar to filter the table by a specific field value, such as a partial string match for a project name.
Project details tabs
The bottom of the Project details page provides additional project information on three tabs: Summary, Metrics, and Recommendations.
Summary tab
The Summary tab shows the starting, current, and change for the following cost and performance data:
- Average cost
- Average runtime
- Average data size
- Average cost per GB
- Market breakdown
- Worker instance type
- Worker count
Metrics tab
The Metrics tab displays additional charts to help you visualize the Daily core hours, number of Workers, Input size in TB, Spill to disk in GB, Shuffle read in GB, and Shuffle write in GB for each job run the selected project.